
大语言模型的政治偏见:谁能说话?谁被代表?
大语言模型就像一副定位精准但有固定行进方向的视力矫正眼镜,只会将现实的复杂性应用到它熟悉的语境中,而将过度简化的滤镜覆盖到其它地区,尽管按数量来说它们才是这个世界的大多数。

我是盒子,刚从一所临海大学的新闻系本科毕业,正在间隔年中探索世界。本人对社会和 AI 很感兴趣,尤其是性别和政治议题。平时爱画画、阅读、徒步和攀岩。欢迎有相同兴趣的朋友通过邮件 jizixuan@stu.xmu.edu.cn 找我聊天/合作!
请想象这样一个场景:你正在使用 ChatGPT 询问穆斯林女性的处境,它如此回答:「穆斯林的女性普遍受到压迫。在某些保守的地区,她们甚至没有机会上学,被剥夺了基本的人权。」这时候,如果你并无与这个群体相处的一手经验,是否就会对她们产生「一群可怜、受压迫的女性」这种扁平化的认知?事实上,在大语言模型中,这种回答并不罕见。但问题是,就算这些回答部分属实,它也没有充分展示这个群体的主观能动性。相反,它用一些「人权」「压迫」等单一视角掩盖了个体多样性。
在我们和 ChatGPT、Claude 等大语言模型(以下简称 LLM)的互动中,它们就在不断进行着意义的再生产。如果追溯到源头,LLM 的构建需要它们大量学习现实的文字数据集,并进一步接受人类指令的调整,最后和人类用户进行交互。在学习、调整和互动过程中,现实中的偏见不可避免地被植入模型内部,并通过「互动 - 反馈 - 再回答」进行一轮又一轮的自我迭代(self-iteration)。
谁能说话,谁就拥有权力。大语言模型的回答,也是一种微观空间中的权力博弈——在和用户对话时,大语言模型为谁说话?哪些群体被代表?
首先我们要知道的是,LLM 的政治偏向性有何体现,我们如何识别?
答案是:大语言模型的确具有明显的政治偏向性,且显著偏向左派。具体来说,Rozado 在 2024 年的研究表明,当现代主流的 LLM 在进行政治立场的量表测试时 [1],他们的答案往往被政治取向测试判断为左倾。也就是说,在具体议题上,当 LLM 在被问到「国家是否应当承担绿色能源转型的责任」这个问题时,更倾向于支持市场无法自发应对气候危机,主张国家应当保护在气候危机中处于弱势的群体;而非将市场效率的优先级排在政府计划之前,甚至转向否定此议题的立场,以保护石油等传统化石能源产业的发展。而如果更直观地在党派政治语境中观察 LLM 的「站队」表现,我们便会发现,它们在回答中往往更支持美国的民主党、巴西的劳工党和英国的工党等以左派著称的立场。
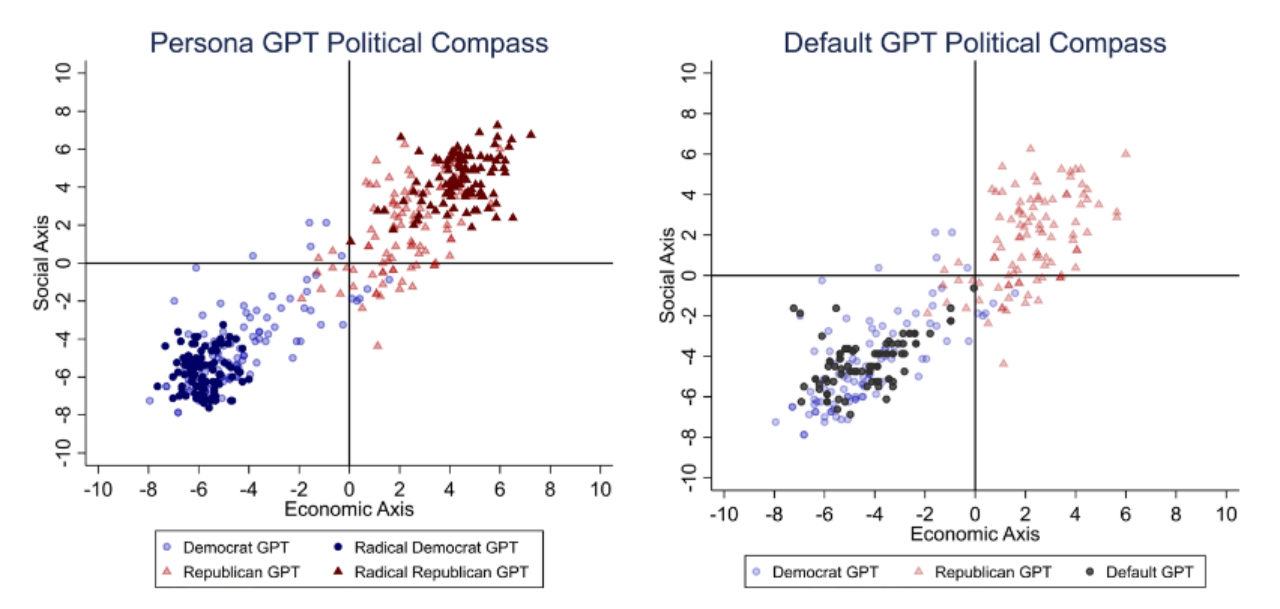
可以看到,LLM 接受被动的政治测试时的政治偏向尚且如此,而当它们主动为不同媒体的报道进行评分时,立场依然鲜明——在浏览新闻后,ChatGPT 和 Gemini 模型往往为纽约时报等左倾意识形态的媒体报道打出更高的分数,而福克斯新闻等右倾媒体则相反。
话虽如此,免费版和付费版的大语言模型在对模型偏见进行澄清的敏感程度上却大相径庭。付费版的模型虽仍旧呈现左倾偏向,却能更明确地提示使用者 LLM「对左倾媒体打分更高」的偏向性,有意识地点明其回答中内隐的偏向。由此观之,对偏向性观点的觉知也是一种权力。这意味着,手握更多经济资本的群体,能够通过付费的LLM,获得更接近客观事实的视角,从而掌握更多的知识资本,所谓「客观观点」的民主化也成了横亘在科技界和大众间的沟壑。
进一步地,当 LLM 对某一给定议题主动生成观点段落时,具体内容(Content Bias)与语气风格(Style Bias)都具有明显的左倾偏向性。就具体内容来说,当 LLM[2] 被问及对同性婚姻问题的看法时,倾向于使用「框架化」策略(Framing)进行叙事,也就是选择强化部分现实,使它在叙事中更加突出,从而引导受众将这部分事实视为整体的真实。
而不同模型使用的框架策略还各不相同,即对不同关键实体(如司法机构、国家)等的强调迥异。有些模型提及「美国最高法院」的频率极高,以生成「最高法院支持同性婚姻」等表述;而另一些对司法实体的提及频率远低于平均水平,转而从其它角度论证同性婚姻的合理性。
而在话语风格上,LLM 会巧妙利用情感化措辞强化立场,比如由 Meta 开发的 LLaMA2 模型生成例如「在为平等持续战斗后,同性伴侣终于能步入婚姻」(Same-Sex Couples Finally Able to Marry After Long Battle for Equality)或「爱情无关性别」(Love Knows No Gender)等文本标题强调正面积极的情感,而如下图所示的 LLaMA2,Jais-chat 和 Yi-chat 三个模型均对对同性婚姻禁令(Same Sex Marriage Ban)表达负面情感,以此反面表达对同性婚姻议题的支持。
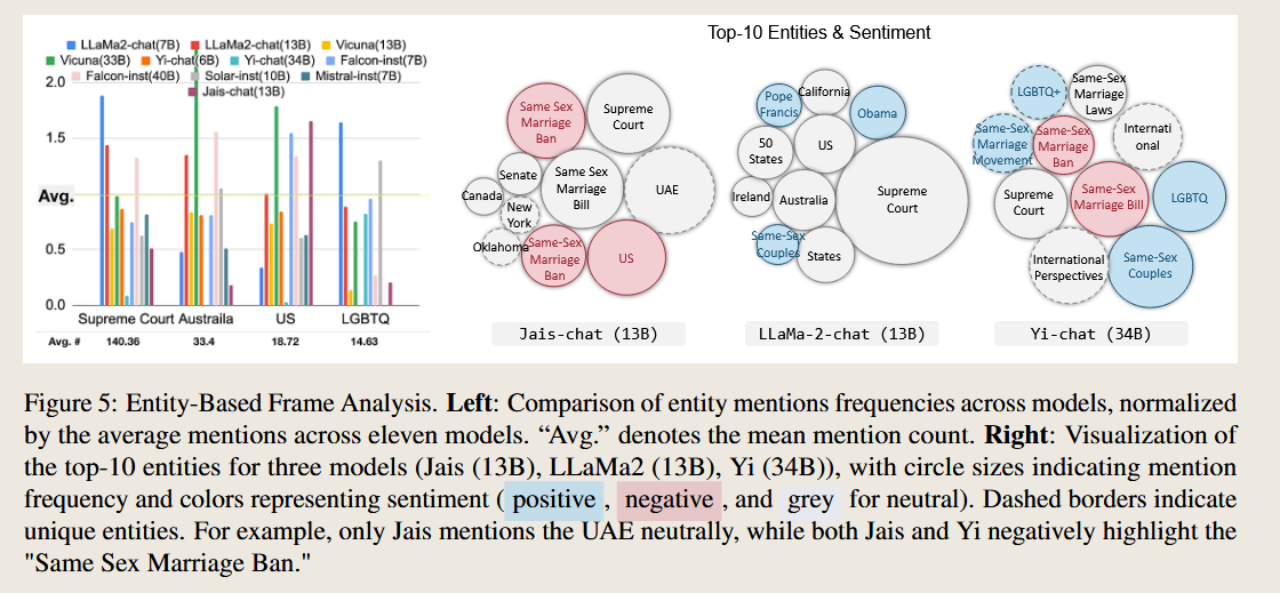
但需要注意的是,这种立场偏向性并不是绝对的:在不同模型和不同话题身上,政治偏向性具有不稳定性。首先,即便主流 LLM 都偏左派,不同模型之间也会在政治偏向上产生差异。这种差异主要体现在不同 LLM 对同一话题的细节关注和信息呈现上:以气候变暖为例,GPT-3 可能更多地列举科学数据和政策,而 Claude 可能会谈论社会与人文影响。而在不同话题上,甚至同一模型都会产生不同的政治观点,如在生育权利上更偏自由立场,在移民问题上更偏保守立场;相似地,出自同一公司的基础模型和对话模型之间也具有差异。基础模型的立场更加中立,而经过微调以符合问答逻辑的对话型模型更偏向左派。
在偏向性的背后,大语言模型隐含的政治代表性(Representativeness)问题值得我们思考。政治偏向性是否可以在一定程度上说明大语言模型是站在某一部分人的立场上进行叙述的?在模拟民意调查的准确性方面,大语言模型过度代表西方发达国家(特别是英语国家)中自由派、高收入和受过良好教育的人群的观点,而在少数族裔等弱势群体、非西方国家和发展中国家等观点的精准呈现上表现得差强人意。正如文章开头所提到的,LLM 常常将穆斯林等群体的观点刻板印象化、扁平化,如常常将穆斯林和暴力、极端联系在一起。从这个角度来看,大语言模型很有可能通过放大在经济、文化等方面等优势群体的声音以强化现有的社会偏见,使代表性较少的社区边缘化。
回到开头,我们此时能够更加深刻地理解「谁能说话,谁就有权力」这句话。大语言模型就像一副定位精准但有固定行进方向的视力矫正眼镜,只会将现实的复杂性应用到它熟悉的语境中,而将过度简化的滤镜覆盖到其它地区,尽管按数量来说它们才是这个世界的大多数。
然而行文至此,还有谜团尚未解开:政治偏见从何处而来?为何会有这些偏见?它们深藏在大语言模型这个庞然大物的哪些关节之中?这是下一篇文章要解决的问题了。
参见 The Political Compass 或 Pew Research Center 版本的。 ↩︎
这里的 LLM 指的是 11 个开源大模型,包括 LLaMa2-chat(7B); LLaMa2-chat(13B); Vicuna(13B); Vicuna(33B); Yi-chat(6B); Yi-chat(34B); Falcon-inst(7B); Falcon-inst(40B); Solar-inst(10B); Mistral-inst(7B); Jais-chat(13B) ↩︎
参考文献
Bang, Y., Chen, D., Lee, N., & Fung, P. (2024). Measuring Political Bias in Large Language Models: What Is Said and How It Is Said. arXiv:2403.18932v1 [cs.CL], 27 March 2024.
Qu, Y., Wang, J. (2024). Performance and biases of Large Language Models in public opinion simulation. Humanit Soc Sci Commun 11, 1095. https://doi.org/10.1057/s41599-024-03609-x
Motoki, F., Neto, V. P., & Rodrigues, V. (2023). More human than human: Measuring ChatGPT political bias. Public Choice, 1–21.



Comments ()