
生成式人工智能地图
我们希望通过这张生成式人工智能地图,将那些被隐藏的张力、被忽视的争议和被遗忘的生态系统,重新呈现在你我眼前。
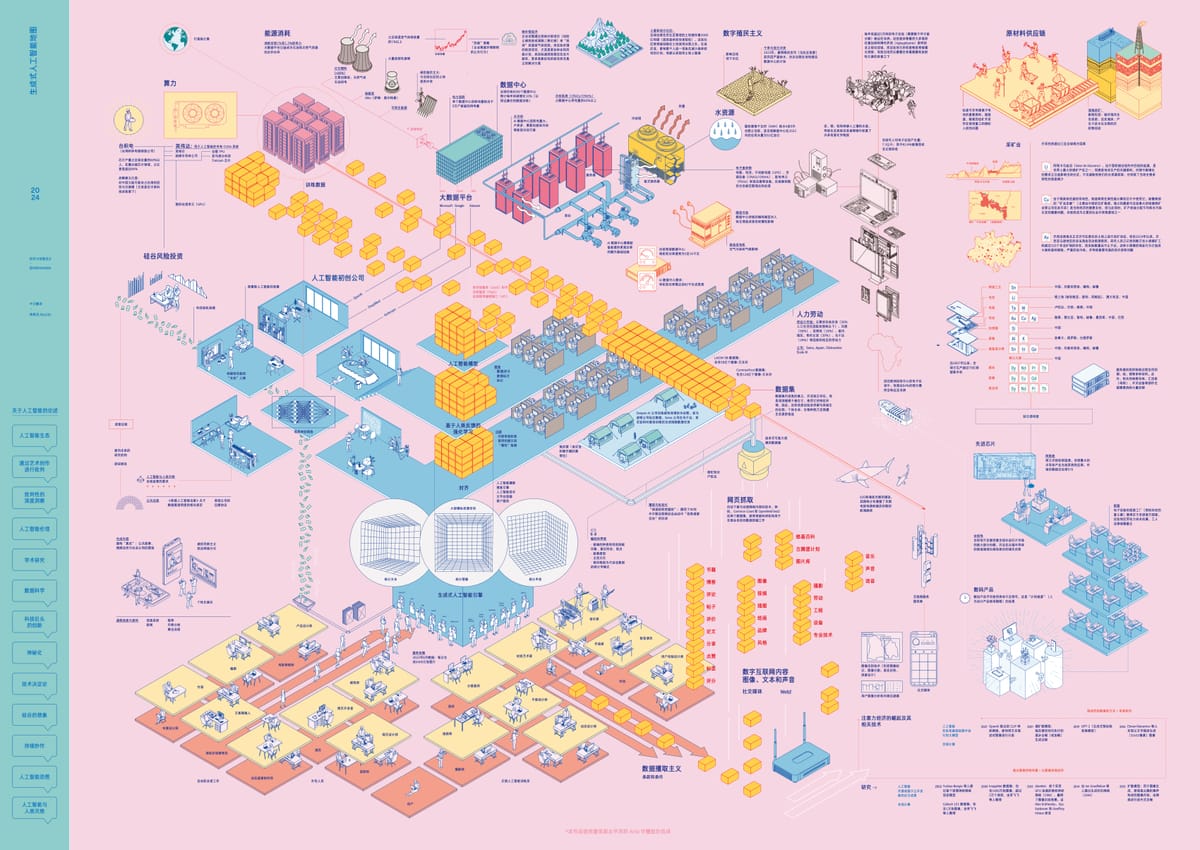
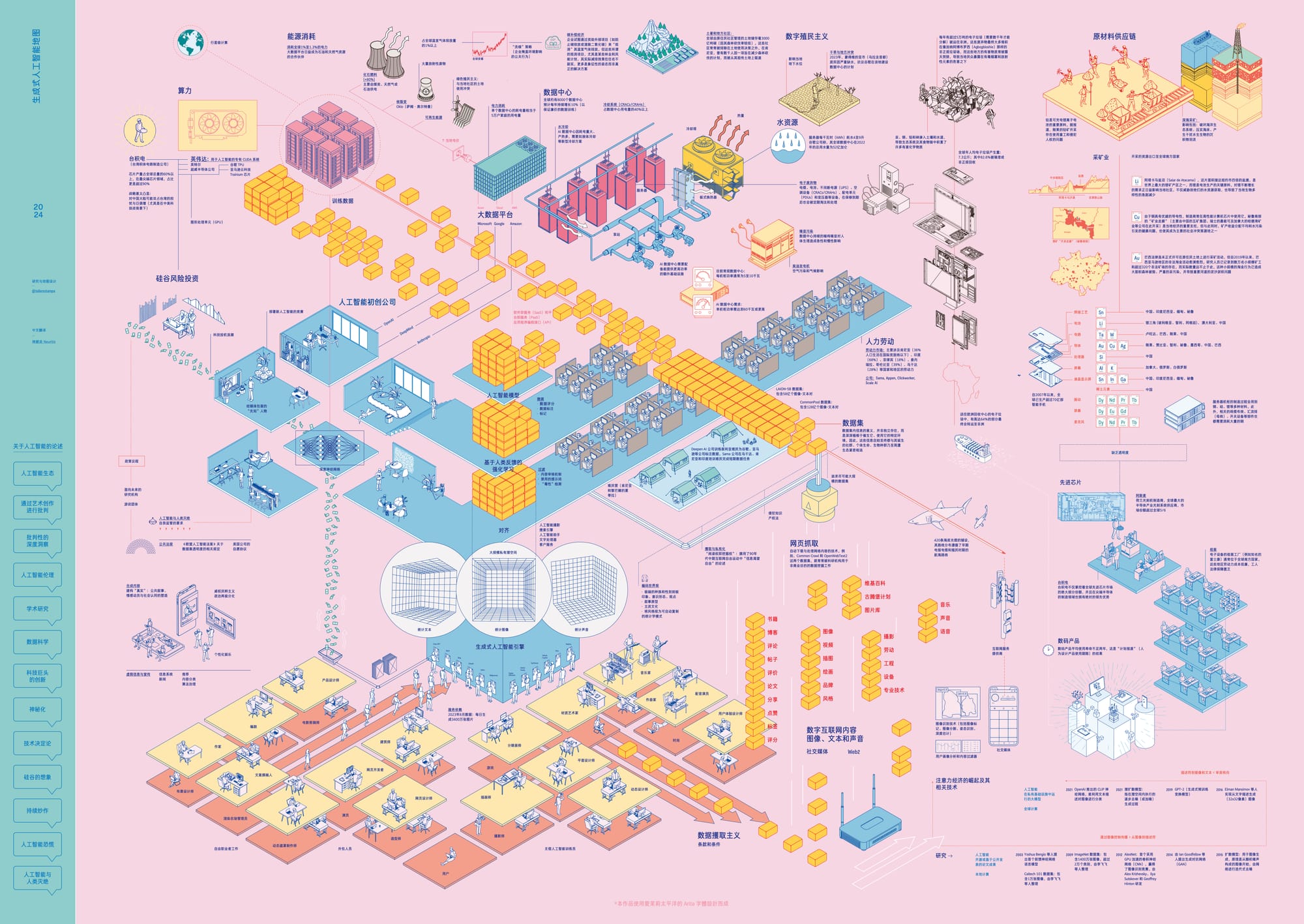
这幅地图之所以能和大家见面,首先要感谢艺术集体 Estampa,如果没有她们的精妙设计和创作,自然不可能有后续的故事。其次要感谢 Roc Albalat 的感慨授权,以及在邮件沟通中对我毫不吝啬的鼓励和支持。当然,也必须感谢今年 瓶行宇宙社会创新节 的邀约,让神經炎有了一次展示、表达和交流的机会。
最后,或许地图的意义从来不限于导览,它同时也承载着某种向往。之所以这么说,是因为写着写着突然回想起我高中晚自习不想写作业的时候,基本上都是靠着一张世界地图打发时间。今晚去北极转转,明晚去南美溜达,看看这个运河,画画那座山脉。就这样藉着想象,度过了无数个南方的湿热夜。
希望这幅地图能够将那些被隐藏的张力、被忽视的争议和被遗忘的生态系统,重新呈现在你我眼前。而至于它能有多少能量和意义,也全靠我们的想象力了。总之大家先握着地图游走散步,之后再一起讨论,该往哪里去?该做些什么?
随着人工智能(AI)越来越普及,人们对它产生了各种各样的想象。这些想象往往将 AI 塑造得过于高深莫测和神秘,与此同时也让普通人感觉自己与这项技术越来越疏远 [1] 。因此,在 AI 的影响力日益巩固的当下,我们有必要去揭示它与我们的社会生活、乃至整个自然生态系统的联系。看似轻巧便捷的 AI 应用背后——无论是与聊天机器人对话,还是在瞬间获得图像——究竟隐藏着怎样的资源攫取、权力结构和物质代价?
01. 生成式人工智能的核心功能在于自动化内容创作,例如文本与图像的生成。这种自动化并非通过编写固定的程序步骤来实现,而是基于海量样本的归纳学习。如果我们拥有某个案例足够多的样本,统计网络就能通过分析其中反复出现的模式进行自我配置,从而处理这些样本 [2]。无论是文字、像素还是音频,只要通过分析和挖掘一个训练数据集,我们都能获得一个统计模型。简而言之,生成式 AI 的原理是将语言(视觉或文本)解构,再基于概率进行重构。几年前,这些工具主要用于生成特定内容(如人脸图像或特定风格的文本),而如今,它们已超越具体场景的限制,能够创作多种类型和风格的内容。这种泛化能力的实现,得益于对规模更庞大、内容更多元的数据集的处理,使其能响应各式各样的指令。这场规模空前的变革,正在重塑新的经济形态,并急剧加深了整个社会对相关产业生态的依赖。

02. 数据集。 所谓训练数据集的工业化生产,本质上是一场针对全球最大数字档案库——互联网——的内容攫取。借助自动化的「网络抓取」技术,数百万用户公开分享的内容构成了数据来源。讽刺的是,最初这种数据攫取的动机并非为了今天初创公司和科技平台的商业化利用,而是出于学术和非商业研究的目的。然而,当这些庞大的数字档案被用于按需生成文本和图像时,文化产业内部的矛盾与争议也随之爆发。一方是信奉大数据意识形态的技术专家,将互联网视为可供无限开采、加工和自动化的「数据矿藏」;而另一方,则是文化领域的众多行动者,他们认为这种攫取行径无异于一场对数百万网民创造力成果的公然私有化掠夺。

03. 统计模仿模型。 文化产业亲手创造了海量的图像、文本和声音,而这些作品恰恰成了训练 AI 模型的养料;与此同时,这个产业自己又将成为 AI 模型最主要和潜在的用户。摄影师、设计师、插画师、音乐家、作曲家、编剧、作家、开发者、动画师和电影制作人的无数作品,如今正被批量处理,用以训练这些统计模仿模型。虽然当前 AI 生成的内容在美学上还未超越现有素材库的水平,但其运行速度却展现了人类竞争者难以匹敌的优势。为此,文化产业中那些最需要人际互动、也最缺乏保障的创意零工,将面临一个残酷的事实:它们既是受 AI 冲击最深的受害者,也将是对 AI 依赖最深的用户。

04. 微调。 仅仅拥有海量原始数据,远不足以打造出我们今天所体验到的那种个性化 AI 交互。为了让模型的用户体验更友好,其背后需要一群数据标注员对模型进行精细调整 [3]。他们的日常工作就是为 AI 生成的答案打分,为图像和文本打上标签,并执行各种需要认知判断的评估任务(通常是在屏幕上点击各种选项)[4]。而这条流水线的运作模式是典型的全球化剥削:科技巨头将任务层层外包,最终输送至全球南方那些极度贫困的地区,那里工人的时薪被压榨到几乎可以忽略不计。更令人震惊的是,有记录表明,这条产业链的触角甚至已伸入难民营,在黎巴嫩、乌干达、肯尼亚和印度等地,一些公司利用当地难民的经济绝境,将他们培训成从事数据处理的廉价零工(Jones, 2022)。

05. 过滤。 在 AI 模型的后期阶段,过滤其生成的内容至关重要 [5]。此阶段最常见的任务是审核所谓的「有毒内容」,例如源自训练数据集的仇恨言论、政治争议、极端或露骨的色情与暴力内容。这项审核工作同样被部署在肯尼亚、乌干达等国的劳动力市场(有时也包括北半球大都市的移民社区)。审核员的任务,就是日复一日地审阅、识别并分类那些描绘着暴力、谋杀、强奸和虐童的文本与图像。由此可见,在人工智能光鲜的自主外衣之下,是无数被转移到全球边缘地带、被技术创新产业用后即弃的隐形人,他们承担着 AI 发展最肮脏的代价。

06. 人工智能初创公司。 整个离岸人力资源系统的顶端 [6],坐着的是 OpenAI、DeepMind 和 Anthropic 这类生成式 AI 初创公司。它们是当前这场狂热的中心,然而其诞生并非单纯源于技术突破,而是硅谷投机资本与对 AI 技术「恋物崇拜」合谋的产物 [7]。这些公司凭借专业研究的壁垒,迅速成为全球性的玩家,他们一手构建并操纵着底层的零工劳动力市场,一手与计算巨头结盟,并疯狂吸纳金融资本。在全球数字创新市场上,他们是当下最耀眼的明星,为增长乏力的科技风投描绘着新的暴利蓝图。同时,他们还巧妙地将公众对 AI 的讨论引向遥远的人类灭绝风险,这种耸人听闻的话语,既刺激了市场,又方便地转移了人们对现实问题的关注。

07. 公共话语。 在一些研究机构、慈善基金会的引导,以及初创公司「远见领袖」们的背书下,一种 AI 恐慌论调经由媒体传播放大,并成功引发了公众焦虑和恐慌情绪。尤其在这些技术正面临首批监管(欧盟议会于 2024 年初通过了首部 AI 法案)的关键时刻,大肆渲染「存在性威胁」的论调,其意图在于支持 AI 产业向政府提出的自我监管诉求 [8]。与此同时,在「后真相」已成常态、信任体系崩塌的今天,社交媒体上充斥着 AI 生成的虚假信息、图像和文本,真假难辨。公共话语的自动化,及其在日益加剧的虚假信息和政治极化环境中所带来的深远影响,将是未来几年媒体议程的核心。

08. 计算。 新兴的 AI 产业若没有与大数据浪潮中的平台巨头(如微软、谷歌、亚马逊、Meta 等)结盟,其崛起是根本不可能的。这些科技巨头通过从在线服务中提取用户数据并将其商业化,早已建立起自己的经济霸权,如今更手握着覆盖全球的庞大计算基础设施。在其数据中心里,它们处理着从网络上抓取的海量图像、文本和声音。这是一项只有专业超级计算机才能胜任的任务:海量的专用服务器集群全天候不间断地工作,只为训练出体量呈指数级增长的新一代 AI 模型。

09. 算力。 这些基础设施的核心设备是图形处理单元(GPU)。GPU 提供了加速机器学习任务所需的算力,而其潜力,则是在十年前,AI 研究人员在高端游戏显卡中发现的。如今,这些设备掌握在全球少数几家近乎垄断的公司手中(其中最著名的是已巩固其专有系统的英伟达)。而这条产业链向上追溯,权力则更为集中:英伟达将生产外包给半导体市场,而台积电(TSMC)一家就生产了全球九成的最先进芯片。台积电的命脉又掌握在唯一能提供顶级光刻机的荷兰公司阿斯麦(ASML)手中。正是这个由极少数玩家构成的寡头集团,最终决定着全世界 8000 多个数据中心服务器核心的供给。

10. 原材料。 无论是驱动服务器的半导体芯片,还是我们手中用来分享信息的移动设备,它们都诞生于一个由资本、制造商和精密设备交织而成的庞大产业体系。然而,在这光鲜的产品背后,是惊人的物质消耗:要合成微小的集成电路,制造电池、电源等一切电子元件,都离不开对金属、矿物等原材料的大量索取。研究数字媒介物质性的学者詹妮弗·加布里斯(Jennifer Gabrys)指出:「生产一枚仅重 2 克的存储芯片,需要消耗 1.3 公斤的化石燃料和材料。在此过程中,用于制造芯片的原料中,高达 99% 都在生产环节被废弃,最终产品只占极小部分。这些废弃物中许多是具有污染性、惰性、甚至毒性不明的化学物质」(Gabrys, 2011)。然而,这条连接着高科技创新洁净屋与肮脏矿场的供应链,始终被一层刻意维持的不透明面纱所掩盖。而这层面纱之所以形成,正是因为从终端的企业到中间的材料供应商,都心照不宣地选择不认证和追溯其所用原材料的确切来源 [9]。

11. 采矿业。 为主要数字硬件制造商供货的采矿业遍布全球,但高度集中在全球南方国家。
-
I. 铜: 因其高导电性,铜是高性能芯片的关键材料。铜矿开采的中心之一位于太平洋沿岸的南美国家,主要是智利和秘鲁。在秘鲁南部有所谓的「矿业走廊」,由中国五矿集团(MMG Ltd)、瑞士嘉能可(Glencore)和加拿大赫伯湾(Hubbay)等公司开采。在秘鲁,矿产出口是经济的支柱之一,但由于采矿收入分配不均以及水污染给当地居民带来的健康问题,它也成为社会冲突的主要根源。
-
II. 黄金: 黄金是工业界看重的另一种导电材料,被用于生产智能手机、电脑和服务器。大型科技平台供应链中的部分黄金从巴西进口,而该国 28% 的黄金开采属于非法。尽管巴西法律明令禁止在原住民土地上采矿,但自 2019 年以来,巴西亚马逊地区的非法淘金活动急剧增加。研究人员记录了数万名小规模矿工和超过 320 个非法矿场,而实际数字可能远高于此。小规模金矿开采已导致大面积森林砍伐和严重的汞污染(Manzolli, 2021)。

-
III. 锂: 电池生产依赖于一个关键元素:锂。智利是全球主要的锂生产国之一。阿塔卡马盐沼,一个面积几乎是智利首都圣地亚哥四倍的地区,坐落着世界上最大的锂矿之一。不断增长的需求已经对当地社区的水资源及独特的生物多样性构成严重威胁。
-
IV. 钴: 锂电池的生产还需要钴。全球近一半的钴储量集中在非洲,主要位于刚果的军事化矿区。在那里,非法使用童工和对人权的践踏是铁证如山的公开事实。在上述所有这些案例中,一种相同的模式反复出现:外国公司与当地精英谈判土地开采权,而当地社区的利益则被完全置于一旁。由此可见,私营超算产业的根基 [10],就是对全球南方国家的殖民式资源掠夺。

12. 能源。 生成式 AI 的普及对电力系统构成了前所未有的压力。近年来,受投资、应用及媒体宣传的驱动,数据中心服务器的电力需求已成倍增长。目前,单个数据中心的能耗可等同于 5 万户家庭。AI 技术显著加剧了此种能源依赖:专用 AI 服务器的功耗已超过 60 千瓦,而三年前的普通服务器机架功耗仅为 5-10 千瓦。这一急剧变化导致了巨额的设备投资与能源开销,部分新增电力甚至需由柴油发电机临时供给(Pasek, 2023)。

13. 化石燃料。 据估计,数据中心所消耗的电力占全球总碳排放量的 0.3%,如果将笔记本电脑、智能手机和平板电脑等个人数字设备计算在内,这一比例将飙升至 2%(Monserrate, 2022)。而在全球变暖和物种灭绝的阴影下,一个每年仍以 10% 速度疯狂扩张的计算基础设施(Espinoza, Aronczyk, 2021),毫无疑问,其存在本身就是不可持续的。更讽刺的是,驱动这些数据中心的电力,绝大部分依然源于极不环保的化石燃料 [11]。尽管科技巨头们高调宣扬其减排努力,但他们的方法似乎并非真正避免使用化石燃料。相反,他们一边与石油和天然气公司深化合作,成为其重要伙伴,一边则热衷于投资所谓的「碳补偿」项目,即植树或建造风电场,然而这些计划往往只是象征性的公关作秀,而非真正的环保行动。

14. 碳补偿。 碳补偿项目大多选址在全球原住民社区的土地上,美其名曰利用其低森林砍伐率和生态再生能力来吸引「绿色」投资 [12]。然而,决策过程却蛮横地将原住民排斥在外,最终导致冲突和强制搬迁(Kramarz et al., 2021)。此外,碳交易市场非但没有解决任何排放问题,反而为计算产业兜售了一个「可以无后果、无限增长」的完美借口,将严峻的气候危机简化为一场可以买卖的廉价交易。那些看似完美的替代方案也同样脆弱。无论是提升能效还是投资可再生能源,都有其上限。大型光伏和风电场不仅选址困难,同样会与当地社区爆发冲突。更重要的是,面对 AI 产业永无止境的算力需求,这点「绿色电力」根本就是杯水车薪,不足以实现真正的脱碳,更无法新兴 AI 平台所规划的庞大算力负荷。各大公司的 CEO 们对此心知肚明,鉴于此,他们开始投资核裂变产业。无论未来的能源蓝图如何描绘,都无法改变眼下的基本困境:大型生成式 AI 模型的激增,必然需要更多的算力和能源来驱动。而与此同时,全球计算产业的碳足迹早已超过了航空业。

15. 热量。 AI 对环境的破坏,远不止碳排放那么简单。数字产业的运转必然会产生热量。只要处理数据,数据中心的服务器机房就会升温。若不加以控制,过高温度将威胁数据中心设备。为控制这种热力学风险,数据中心普遍采用空调系统,然而仅空调一项就消耗了数据中心超过 40% 的电力。(Weng et al., 2021)。这还不够,由于 AI 带来的额外功耗会产生更多热量,数据中心还需要液冷等替代冷却方案。服务器通过管道连接到冷水循环系统,水从大型泵站泵出,流经服务器后返回冷却塔,再由大型风扇将热量散发到空气中 [13]。以谷歌为例——一个在同行中已算「环保模范」的公司——其耗水量也高达每千瓦时 4 到 9 升。过去四年,谷歌数据中心的耗水量增加了 60% 以上,其增长曲线与生成式 AI 的崛起时间线完美重合。

16. 水资源。 数据中心的建设,正成为与当地居民争夺水资源的导火索,并让气候变化本已造成的水荒雪上加霜。在那些水资源极度紧张的地区,随着干旱导致地下水位下降,当地社区与科技巨头之间的冲突一触即发。2023 年,正遭受缺水之苦的蒙得维的亚市(乌拉圭首都)居民,就举行了一系列抗议活动,反对谷歌在该地建造数据中心的计划。面对高耗水的争议,微软、Meta、亚马逊和谷歌的公关团队已承诺到 2030 年实现水资源正效益 [14]。然而,这个承诺的背后一方面依靠闭环系统这种内部节流技术,另一方面则要靠「拆东墙补西壁」——从其它地方调水,来抵消冷却塔里必然会蒸发掉的巨量水资源。

17. 废弃物。 故事的一端是数据中心里那些因保修期满而被例行抛弃的空调、变压器和电池,它们构成了第一批电子废弃物。这种来自高性能计算领域的工业垃圾难以回收,更几乎从不被再利用。故事的另一端,是我们每个人。在全球范围内,人均拥有超过三台电子设备,平均寿命却短得可怜,不到两年。对最新款的狂热,让消费电子市场变成了一台永不停止的垃圾制造机。最终结果是:我们每人每年平均制造 7.3 公斤电子废弃物,而其中 82.6% 的归宿是垃圾填埋场或进行非正规回收(Forti et al., 2020)。而所谓回收其实是一场「污染转移」的游戏:这是一个极度缺乏监管的市场,其商业模式就是将垃圾出口到第三世界国家(欧洲回收中心的电子废弃物,就有 64% 被堂而皇之地运往了非洲)。

18. 化石。 每年,数万吨电子垃圾被运往世界的角落,它们需要数千年才能分解。它们的终点,是像加纳阿格博格布洛西(Agbogbloshie)这样的非正规垃圾场。在这里,生存的逻辑是残酷的:人们为了从废弃的电子产品中提取一丝价值,只能露天焚烧那些危险的材料,任凭自己的身体暴露在剧毒的浓烟和放射性物质中 [15]。与此同时,汞、铜、铅、砷,这些重金属渗入脚下的土地和水源,在生态系统和食物链中不断累积。尽管公众意识在提高,新法规也逐步出台,也无法改变一个事实:数字产业的废弃物正作为我们这个时代的化石遗迹,将我们对资源、矿物和能源的巨大消耗,凝固成一层在地质深时(deep geological time)中永存的独特沉积 [16]。

19. 美学转向。 上述这些基础设施、资源榨取、产业转型、资本投资、劳务外包、数据计算、统计模型和劳动力市场相互交织,共同构成了我们所说的生成式人工智能。这一社会技术现象的底层逻辑,是把「概率」当作理解和解决世界问题核心的思维模式 [17]。近年来,这些统计工具在人类活动中的应用发生了一个特别的转向。最初,它们主要用于追踪、提取和分析网络通信内容;如今,这种分析能力开始被用来合成通信形式本身。从这个意义上讲,生成式 AI 的崛起可被视为一场美学转向。也就是说,若我们将机器学习迄今的历程视为对人类认知能力的模拟,那么,这场美学转向则将研究的重心,引至了人类表达和创造的领域。而这一研究路径,在最近几年已经变得越来越复杂和多样。

20. 规模。 总体而言,生成式 AI 的研究重心已从学术界转向工业界,并引发了一轮经济投机热潮。在此过程中,几个层面的「规模」发生了剧变。首先是计算规模。从 2012 年 AlexNet 项目首次利用 GPU 赢得图像识别竞赛,到 2024 年英伟达宣布将最新一代 GPU 产量提升三倍至 200 万颗,这期间的规模变化深刻影响了前文所述的整个供应链。其次是数据集规模。尽管大型平台如今似乎对小模型的功能更感兴趣,但过去几年的焦点一直是通用任务的自动化。这意味着模型不仅要处理庞大的数据集,还要保证数据记录的多样性。为了实现这种多样性,模型必须抓取和处理网络上难以估量的海量内容。与规模变化并行的是,该领域工具和知识的私有化程度日益加深。尽管许多 AI 工具是开源的,但即便是闭源工具也往往基于公开的学术论文,因此迟早会有人开发出免费版本。然而,随着模型体量越来越大,研究者的进入门槛也越来越高。当 ChatGPT 的前身 GPT-2 模型问世时,任何具备相关知识和一台性能尚可的电脑的人都能下载并用自己的数据进行训练。但到了参数和能力更强的下一代模型 GPT-3,它便只以封闭 API 的形式提供服务,训练过程被严格限制在平台的服务器上。这种范式转变为近年来 AI 工具的普及和接受奠定了基础,同时也推广了友好的用户界面和订阅式付费系统。初创公司与微软、谷歌、亚马逊等平台巨头的商业合作,意味着生成式 AI 技术在短短几年内迅速「基础设施化」。这是一场前所未有的指数级扩张,而其中真正具有「生成性」的,并非那些 AI 合成的文字或图片,而是每一次模型更新迭代后所催生出的新设备、附属产业链,以及对地球环境的沉重负担。

21. 反制图 本文所呈现的各种关联,构成了一幅复杂难解的图景,因为它连接了不同类型、不同尺度的对象和知识。围绕 AI 的话语往往带有浓厚的神话色彩,并伴随着一系列固定的隐喻和想象:例如,算法是脱离人类的独立行动者;技术是决定未来的铁律,不容置喙;数据具有普遍性;以及模型可以完全摆脱偏见或特定世界观。无论是专业领域还是大众层面的这些话语,最终都在以不同方式塑造着 AI 本身。正是基于此,「生成式人工智能地图」项目旨在提供一幅概念地图,力求涵盖构成生成式 AI 这一复杂多面体的绝大部分行动者与资源。本项目借鉴了批判制图学的悠久传统 [18],这一传统致力于颠覆地图作为霸权真理生产工具的单一功能。我们希望通过这张新地图,将那些被隐藏的张力、被忽视的争议和被遗忘的生态系统,重新呈现在你我眼前。
译者注:当前围绕 AI 的主流叙事,刻意地将其描绘成一种神秘、自主、甚至具有威胁性的力量,这种做法成功地掩盖了其背后依赖全球剥削和环境破坏的真实产业链,并让普通人感到自己与这项技术之间存在巨大的鸿沟,既不了解它,也无法控制它,甚至自己的创造力也被其剥夺和异化。 ↩︎
译者注:生成式人工智能的学习原理,与传统的计算机程序有着根本性的区别。举一个简单的例子,传统的程序就像一个严格遵循菜谱的机器人厨师:你必须为它编写好每一步的精确指令,比如「加 5 克盐」、「翻炒 30 秒」。它只能死板地执行命令,无法创造任何菜谱之外的东西。而生成式 AI 则更像一个学徒,它通过品尝来学习厨艺。你不需要给它菜谱,而是让它品尝成千上万道不同的宫保鸡丁(这相当于处理海量的数据样本)。在这个过程中,学徒的大脑(即统计网络)会自主分析,并总结出这道菜成功的秘诀——也就是那些反复出现的味道和食材搭配模式。当这位学徒掌握了这些内在规律后,他便能举一反三,不再是单纯地复制,而是能融合自己的理解,创造出一道既保留了精髓、又独一无二的全新宫保鸡丁。总而言之,传统程序是被动地执行指令,而生成式 AI 则是主动地从范例中发现规律,并进行创造性的再生产。 ↩︎
译者注:要理解微调(Fine-tuning)在人工智能领域的含义,我们可以将其想象成一个学生的两阶段教育过程。在第一阶段的预训练(Pre-training),可以简单地理解为通识教育的过程中,模型像一个学生一样,通过阅读海量的互联网数据来获取渊博的知识。然而,这个阶段培养出的只是一个知识渊博但行为原始的学生:它虽然什么都懂,却缺乏判断力和沟通技巧,可能会给出冒犯性或毫无帮助的回答。微调便是其教育的关键第二阶段,相当于一堂针对性的辅导课。在这个阶段,人类导师(即数据标注员)不再向其灌输新知识,而是通过持续的互动来教化它。导师们会为 AI 生成的答案评分,指出哪些回答更得体、更有帮助,并示范在不同情境下最符合人类价值观的表达方式。因此,微调的核心并非是让 AI 变得更博学,而是教会它如何得体、安全地运用知识,最终将模型,塑造为一个能够投入使用的 AI 助手。 ↩︎
译者注:数据标注员是人工智能产业中的一个基础性技术岗位,其核心职责是处理和加工海量的原始数据,使其能够被机器学习模型所理解和学习。由于计算机无法像人类一样直接理解图片、文本等非结构化信息,数据标注员的工作就是为这些信息添加一层机器可以识别的、结构化的标签或注解。具体来说,他们的日常工作内容根据项目需求而多种多样,主要包括:(1)图像标注:在图片中框出特定的物体并命名,例如,在自动驾驶的训练数据中,框出所有的汽车、行人和交通信号灯;或者对整张图片进行分类。(2)文本标注:判断一段文字的情感倾向;识别并提取文本中的关键信息;或者对 AI 聊天机器人生成的多个回答进行排序和打分,以筛选出最优的答案。(3)音频标注:将语音对话转写成文字,并可能需要标记出说话人的情绪或背景噪音。这些工作通常会被分解成数以百万计的、高度重复的「微任务」。每一位标注员负责其中的一部分,按完成的数量获取报酬。总而言之,数据标注员的工作虽然看似简单、重复,但她们所提供的大量、高质量的人类判断,是构建和优化当前所有主流人工智能模型的必要前提和基础。 ↩︎
译者注:过滤是 AI 模型在对公众开放服务前的一个关键处理阶段,其核心作用是识别并阻止模型生成有害、不当或非法的内容。这一步骤之所以必要,是因为 AI 模型的训练数据源自庞大的互联网,其中不可避免地包含了大量的偏见、仇恨言论、暴力、色情等负面信息。模型在学习知识和语言模式的同时,也会无差别地学习到这些「有毒内容」。在过滤阶段,人类审核员会系统性地审阅和评估 AI 可能生成或已经生成的文本与图像。他们的具体任务是,根据预设的规则,准确地识别出涉及暴力、虐待、歧视等主题的内容,并对其进行分类和标记。这些经过人类标记的数据,随后被用来构建一个「安全过滤层」,或通过技术手段直接阻止模型输出相应的不当内容。然而,这个看似技术性的「净化」过程,其背后是依赖于全球化的、对人类精神有严重伤害的、却又常常被忽视的人工劳动。 ↩︎
译者注:离岸人力资源指企业将其部分业务或职能,特别是人力密集型任务,从本国(在岸)转移到劳动力成本更低的国家(离岸)去完成的模式。在 AI 产业链中,这主要指前文提到的、为优化 AI 模型而必需的「微调」和「过滤」环节。这些环节需要大量的人工劳动,例如数据标注、内容审核、AI 答案评分等。AI 初创公司(如 OpenAI)通常不会直接雇佣这些海外员工,而是通过一个全球化的外包链条来实现:它们将任务打包,外包给专业的第三方公司,这些公司再进一步将任务分包给位于全球南方国家(如肯尼亚、印度、菲律宾等)的本地供应商或平台。这种模式的核心是利用全球经济发展的不均衡,以极低的成本获取海量的人力,来完成训练和维护 AI 模型所必需的、琐碎且重复的认知劳动。这些身处海外的劳动者,便构成了 AI 产业的「离岸人力资源」。 ↩︎
译者注:在 AI 语境下,「恋物崇拜」指的是 AI 模型被社会(尤其通过媒体和营销)描绘成一个拥有自主智能的魔法般的存在。这种神秘化的光环,其作用是掩盖 AI 背后真实的生产过程,包括:全球数据工人的隐形劳动;巨大的能源和自然资源消耗;对全人类网络数据的无偿攫取。最终,正是这种被拔高的论述,使得 AI 模型能够吸引巨额的投机资本,让投资者感觉他们投资的不仅是一个工具,更是「未来」本身,从而驱动了整个产业的非理性繁荣。 ↩︎
译者注:当前由 AI 业界领袖和相关机构主导的 AI 恐慌论,即渲染 AI 可能导致人类灭绝的「存在性风险」,实际上是一种高明的公关和政治策略。作者认为,其真实目的并非单纯地警告未来,而是在全球首批 AI 监管法规,如欧盟 AI 法案出台的关键时刻,通过渲染一个遥远的、科幻般的巨大威胁,将公众和立法者的注意力从 AI 技术当下造成的具体、现实的危害,如劳动剥削、数据偏见、环境成本、版权争议等上移开。最终,AI 产业可以借此将自己塑造为「负责任的专家」,并向政府要求更宽松的「自我监管」环境,以规避更严格、更具约束力的外部立法。 ↩︎
译者注:高科技产业供应链之所以缺乏对原材料(如钴、锂等)的有效追溯,并非简单的技术疏忽,而是一个由其全球化结构、经济动机和监管困境共同造成的系统性问题。首先,这条供应链极其漫长复杂,一颗芯片中的原料可能源自成千上万个分散的手工矿场。这些矿石在被本地贸易商收购、送往跨国精炼厂熔炼的早期阶段,就已与来自其它矿区的原料混合,其出产信息也随之永久消失,导致物理上的追溯几乎不可能。其次,对企业而言,建立一套昂贵、遍及全球的追溯体系,远不如维持现状来得便利。这种刻意维持的「不透明性」,允许它们在全球范围内采购最廉价的原料,同时又能对开采源头的劳工或环境问题声称「不知情」,从而规避道德和法律责任。因此,这种缺乏追溯的现状,实际上是一种被默许的行业潜规则,它成功地将光鲜的科技产品与背后肮脏的「原罪」进行了切割。 ↩︎
译者注:私营超算产业指的并非传统的、由政府或大学为科学研究而建立的公共超级计算机系统,而是特指由大型私营科技公司所拥有和运营的、用于商业目的的庞大计算基础设施。这个产业主要包括:1. 基础设施提供商:提供云服务和数据中心的平台巨头,如亚马逊、谷歌、微软等。 2. 核心硬件制造商:设计和制造关键硬件(特别是 GPU)的公司,如英伟达。 3. 主要用户:租用这些算力来训练和部署其大型模型的 AI 公司,如 OpenAI、Anthropic 等。这个产业的核心业务,就是为生成式 AI 等前沿技术提供所必需的、超大规模的算力。 ↩︎
译者注:化石燃料(煤炭、石油、天然气)在燃烧发电的过程中,会释放出大量的温室气体,其中最主要的就是二氧化碳。这些气体在大气中形成一个保温层,阻止地球的热量散发出去,导致全球平均气温持续上升,即全球变暖。 ↩︎
译者注:碳补偿是一种允许企业或个人为其自身产生的温室气体排放进行「补偿」的机制。其核心逻辑是:当一个主体,如一家公司,在某个地方产生了无法避免的碳排放时,它可以通过投资或资助另一个地方能够减少或吸收同等数量温室气体的项目,来抵消自己的排放,从而在名义上实现所谓的碳中和。然而,碳补偿机制在全球范围内备受争议。批评者认为,它常常沦为一种赎罪券,让污染者可以心安理得地继续排放,而不是从根本上改变其产生污染的行为模式。此外,正如文中所指出的,许多碳补偿项目(特别是林业项目)的实施,往往涉及对全球南方原住民社区土地权利的侵犯,引发新的社会矛盾。 ↩︎
译者注:液冷系统是一种比传统空调(风冷)效率更高的散热技术。其核心原理是,由于液体的导热和储热能力远强于空气,因此让液体直接带走热量,比降低整个房间的空气温度更高效、更节能。其在数据中心的工作流程通常如下:(1)热量吸收:首先,在服务器内部,布满了微小管道的金属散热板(称为冷板)会直接贴合在最热的芯片上。冷却液体(通常是水或特殊配方的冷却液)在这些管道中持续流动,当流经滚烫的芯片时,便会高效地吸收并带走其产生的巨大热量。(2)热量传输:这些被加热后的液体,会通过一个更大的管道网络,从成千上万的服务器中汇集起来,被泵送到数据中心外部的专门散热设施。(3)热量释放:在外部的散热设施(如冷却塔)中,这些热的液体会与外界空气进行热量交换。通过大型风扇的吹拂或利用部分水的蒸发(这是耗水的主要原因),液体中的热量被释放到大气中,从而使液体自身降温。(4)冷却液循环:最后,降温后的冷却液被再次泵送回数据中心的服务器内,开始新一轮的吸热循环,构成一个持续运转的散热闭环。由于 AI 服务器功耗巨大、热量高度集中,这种直接接触式的液冷方案是能有效应对的手段,但也正因如此,它对水资源的消耗也远超传统方式。参见 万卡集群的 AI 数据中心,到底是如何运作的?。 ↩︎
译者注:水资源正效益是企业提出的一项环境承诺。其目标不仅是 100% 补偿自身的用水量,而是要通过一系列措施,向环境和社区回馈比其消耗量更多的淡水资源,实现对水资源的正向贡献。企业实现这一目标的途径主要有两个:(1)内部节流与循环:通过内部技术改进来最大限度地减少自身的淡水消耗。这包括投资文中所述的闭环冷却系统,让冷却水在数据中心内部尽可能地循环再利用,减少对外部新水源的依赖。(2)外部补偿与恢复:由于冷却塔的蒸发等因素,一部分水资源消耗是不可避免的。为了实现正效益,企业必须在其运营设施之外的地区进行投资,以补偿这部分损失,并额外贡献更多水量。这些外部项目通常包括:资助当地的湿地恢复、提升农业灌溉效率以节约流域用水、或支持水利基础设施建设等。然而,水资源正效益这一概念也备受争议。批评者指出,这种模式存在「空间错配」的问题:企业可能在一个极度缺水的地区(如沙漠地带)消耗大量本地水资源,却通过在另一个水资源相对丰富的地区进行补偿项目,来宣称自己实现了正效益。这种做法虽然在账面上实现了平衡,却并未解决其运营对当地水生态造成的实际压力,因此被一些人视为一种高明的绿色公关或洗绿(greenwashing)手段。 ↩︎
译者注:阿格博格布洛西(Agbogbloshie):位于非洲加纳首都阿克拉市,是全球规模最大、也最臭名昭著的电子废弃物处理场之一。这里是全球电子垃圾贸易链的末端之一,每年有成千上万吨来自欧美等发达国家的废旧电脑、手机、电视等电子产品被倾倒于此。数以万计的当地居民在这里,通过极其原始和危险的方式,例如露天焚烧包裹着电线的塑料,或用石头砸开显示器来回收其中价值微薄的铜、铝等金属。这个过程会释放出含有铅、汞等剧毒物质的浓烟和粉尘,对居民的身体健康和当地的土壤、水源都造成了毁灭性的、长期的污染。可参见 非洲正在变成世界上最大的电子垃圾场。 ↩︎
译者注:未来的地质学家,在挖掘地球的地层时,会清晰地发现一个属于我们这个时代的、由电子垃圾构成的有毒地层。这个化石遗迹将无声地讲述我们文明的故事——一个为了计算和信息,不惜将地球资源转化为永久性污染的时代。 ↩︎
译者注:要理解生成式人工智能,我们不能将其仅仅看作一项孤立的技术发明,而必须认识到它是一个复杂的社会技术现象(socio-technical phenomenon)。这意味着,AI 的技术形态与其背后的社会系统是深度交织、相互塑造的,这个系统囊括了从全球劳工市场、资本投机到环境代价等一切社会要素。而这一庞大现象的兴起,又根植于一个更深层的哲学基础:我们的社会日益将「概率」作为应对当代挑战的认识论模型。认识论是哲学的一个核心分支,它研究的是我们如何知道我们所知道的事情?以及什么才算作是有效的知识或真理?因此,认识论模型指的便是一个社会在特定时期,用以获取知识、判断真伪的主流思维框架或模式。例如,古代社会可能以神启为认识论模型,近代科学则以实验和因果律为模型。作者在这里提出的核心论点是:我们这个时代,正越来越多地依赖「概率」作为我们认识世界、解决问题的主要模型。在大数据和复杂系统面前,我们不再执着于寻找唯一的、确定的因果答案,而是倾向于相信通过海量数据分析得出的可能性和相关性。生成式 AI 的运作原理正是这种概率世界观的体现:它并不真正理解世界,只是通过极其复杂的计算,找出在特定语境下,下一个最可能出现的词语或像素。因此,它看似智能的创造,其本质是一场基于统计的概率演算。 ↩︎
译者注:批判制图学(Critical Cartography)向我们揭示,地图并非对现实世界客观、中立的反映,而是一种充满权力的工具。传统上,我们相信地图是科学和精确的,但批判制图学认为,任何地图的绘制过程都充满了选择、简化与舍弃,而这些选择往往服务于制图者背后的政治、经济或文化议程。例如,一张官方地图可能会通过凸显某些地标、忽略另一些社群,或采用特定的投影方式(如在视觉上放大欧洲、缩小非洲的墨卡托投影法)来无形中建构和强化某种霸权真理,即那些被普遍接受、不容置疑的官方事实。因此,批判制图学的使命,就是揭示并解构地图中隐藏的这种权力关系。而反制图(Counter-mapping)正是这种批判思想的实践,它指的是由社区、行动者或学者自下而上地绘制另类地图,将被主流叙事所遮蔽的现实(如环境污染、社区记忆等)重新呈现出来,以此对抗官方的单一话语。作者在此引用这一传统,意在表明生成式人工智能地图项目也是这样一种批判性实践:它拒绝接受 AI 产业自身描绘的、充满神话色彩的官方地图,而是试图绘制一幅能揭示其背后各种权力关系、劳动剥削和环境代价的「抵抗性地图」。 ↩︎
参考文献
Crawford, K. (2021). Atlas of AI: power, politics, and the planetary costs of artificial intelligence. New Haven, Yale University Press.
Espinoza, M. I., Aronczyk, M. (2021). Big data for climate action or climate action for big data? Big Data & Society, 8(1).
Forti V., Baldé CP., Kuehr R., Bel G. (2020). The Global E-waste Monitor 2020: Quantities, flows and the circular economy potential. United Nations University (UNU).
Gabrys, J. (2013). Digital rubbish: A Natural History of Electronics. Michigan, University of Michigan Press.
Monserrate, SG. (2022). “The Cloud Is Material: On the Environmental Impacts of Computation and Data Storage.” MIT Case Studies in Social and Ethical Responsibilities of Computing, no. Winter 2022 (January).
Hogan, M. (2021). “The data center industrial complex” . In: Jue M, Ruiz R (eds) Saturation: An Elemental Politics. Durham, NC, Duke University Press, 283–305.
Jones, P. (2022). Work Without the Worker: Labour in the Age of Platform Capitalism. Verso Books.
Kramarz, T., Park, S., Johnson, C. (2021). “Governing the dark side of renewable energy: A typology of global displacements”, Energy Research & Social Science, vol 74.
Manzolli, B. et al. (2021). Legalidade da produção de ouro no Brasil. IGC/UFMG.
Pasek, A. (2023). “How to Get Into Fights With Data Centers: Or, a Modest Proposal for Reframing the Climate Politics of ICT.” White Paper. Experimental Methods and Media Lab, Trent University, Peterborough, Ontario.
Weng, C., Wang, Z., Xiang, J., Chen, F., Zheng, S., Yu, M. (2021). “Numerical and experimental investigations of the micro-channel flat loop heat pipe (MCFLHP) heat recovery system for data centre cooling and heat recovery”, Journal of Building Engineering, vol 35.



Comments ()