大模型也内卷?基准测试的认识论
我们需要更全面、负责任的评估方法,超越单纯的数字竞争,跳出竞技场上的应试逻辑,放下对测量一切的痴迷,重新定义进步是什么。

大模型排名都是怎么打分的?相信你最近肯定刷到过不少科技新闻,标题赫然写着:“ChatGPT 击败 Gemini,登顶全球 AI 排行榜!”或者“Grok 3 性能飙升,超越前代模型 50%!”那么这些排名到底是怎么算出来的?是看谁先算出某道数学题的答案吗?
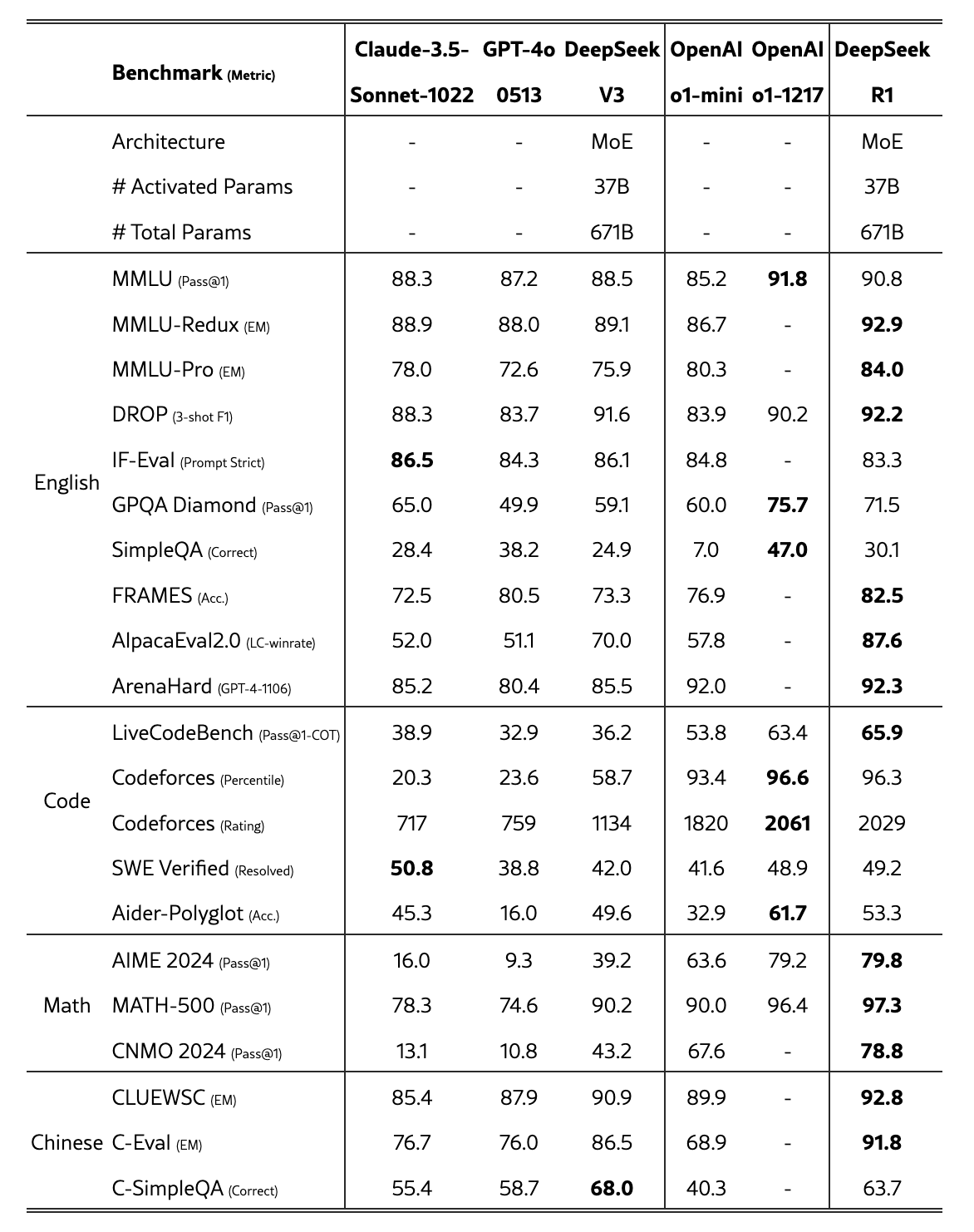
在 AI 研究中,为了判断一个大模型有多“聪明”,研究者们设计了一套标准化的方法,叫做基准测试(benchmarking),有点像给 AI 出卷子考试。这些“卷子”由数据集和评估指标组成:数据集提供题目,比如翻译句子或者回答问题;评估指标则是评分标准,比如准确率或者流畅度。通过这些测试,我们才能知道一个模型在各种任务上表现如何。常见的试卷有英文、代码、数学和中文,下图便是 DeepSeek-R1 和其它几个常见模型的考试成绩,可以看到 DeepSeek-R1 的中文成绩明显地要高于其它同类模型。总之,通过这些考试就能排出 AI 界的榜单了。
然而,事情没那么简单——基准测试看似公平,却可能隐藏着缺陷,比如题目设计不够全面,或者模型学会了“应试技巧”却实际上却不实用,模型会不会“作弊”拿高分?今天想和大家分享的这篇论文很有趣,作者以历史的视角,带我们穿越基准测试的演变历程,揭示它如何从协作工具变成竞争性指标,并探讨生成式 AI 时代对它的挑战。接下来就让我们试试走进 AI 的“竞技场”,从头解开大模型排名的秘密。看看基准测试从哪里来,又会去向哪里?以及它又有什么隐藏的危机。